我們已經知道了組成一個簡單的 CNN 所需要的部件了,那麼接著我們就需要使用 Pytorch 的 Tool 來建構一個真實能夠動的 Model來看看效果了~
以下以 Classification 為例,目的為快速帶過實作所有需要的部件來讓大家理解,後續實作時就不會對名詞那麼陌生:
我們拿 Pytorch 官網的 tutorial 來進行說明,一般來說我們要建構一個 CNN 的 model 並進行 training 以及 Testing , 我們需要完成以下幾件事:
為了方便給大家練習,我們建議使用很常在網路上找到一堆人介紹過的 Colab 來練習,相關文章可以參考這個~
這一章中的 "使用 Dataset" 為使用 Pytorch 官方的 Torchvision 庫,未來我們自己在做人臉技術時則是會使用自己準備的 dataset 喔~ 另外 Torchvision 也不只能夠載資料集還能處理資料或者進行 data augmentation!
Torchvision 是一個 Pytorch 官方維護的資源庫,裡面主要收錄三大類資源:
pip install torchvision
一些document跟各別function或者提供的內容可見官網
好啦我知道你們碗真的要敲破了XDDD難得的來寫一下基本的使用情況吧。我分成4步來示範一下使用 Torchvision 大概會長啥樣:
在安裝完或者已經有現成的環境中,我這邊以開啟 Colab 做示範, 使用下方程式碼來引入 Pytorch 跟 Torchvision :
import torch
import torchvision
接下來按下執行沒有報錯基本上就是有成功引入,當然我們也可以藉由查詢版本的方式再一次確認真的有抓到:
torch.__version__
torchvision.__version__
執行完的結果如下: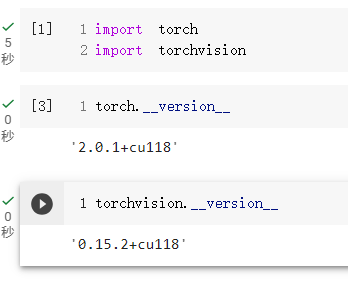
在 Torchvision 上有非常多的Dataset可以使用詳可見官網連結,那我們今天使用的也是簡單的例子"Cifar 10",這是一個小小的dataset,每張照片為32 X 32 RGB照片並且有相對應的 Label,我們以官網的tutorial來說明:
0. Import 必須資料庫
import torch
import torchvision
import torchvision.transforms as transforms
1.使用下面指令可以下載Cifar 10 的Training dataset 以及 Testing dataset
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
畫面會長成這樣: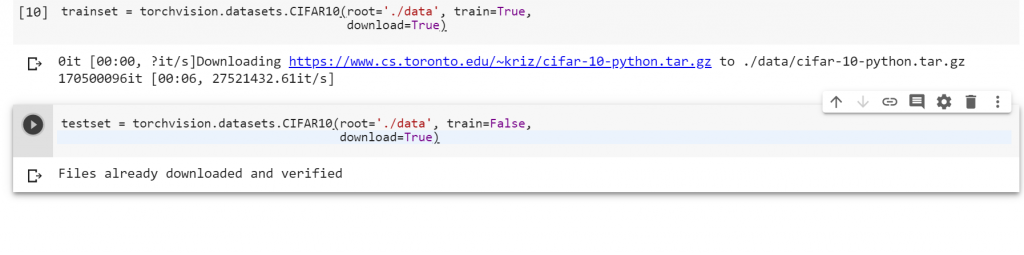
2.使用 Dataloder 讀進這些 dataset 並加上 label
Dataloder是用來讀這些dataset的工具,目前我們先使用 pytorch 本身的dataloder即可,我們會在之後的實務篇章裡講解一下dataloder內部細節以及如何自訂義 dataloder來讀自己的 face dataset
預先打 transform 的形式,這個用來把dataset做轉換,這邊只是先轉換成 Tensor 的型態
transform = transforms.Compose(
[transforms.ToTensor()])
先打 Tarining 跟 Testing dataset 的 dataloder
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=2)
接者加入label 種類
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
3.我們讓dataset 顯示
使用 matplot 來顯示:
import matplotlib.pyplot as plt
import numpy as np
# functions to show an image
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# get some random training images
dataiter = iter(trainloader)
images, labels = dataiter.next()
# show images
imshow(torchvision.utils.make_grid(images))
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))
並可以得到以下結果:
如上節所看到的,我們可以藉由設置 "transform" 來設定我們想對 dataset做甚麼多的處理
例如:
transform = transforms.Compose(
[transforms.ToTensor(),
transform.Translation(),
transforms.RandomHorizontalFlip(p=0.5)
])
我們可以得到類似以下效果:
這邊我們就只貼上 Code 吧 :
import torch
import torchvision
import torchvision.transforms as transforms
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
首先,讓我們來定義我們的神經網路模型。以下是完整的程式碼,然後我們將逐一解釋每個部分和函數的意義,部分資訊我就直接打在註解上了:
import torch.nn as nn
import torch.nn.functional as F
# 定義一個繼承自 nn.Module 的類別,表示我們的神經網路模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 第一個卷積層:輸入通道 3(彩色圖像),輸出通道 6,卷積核大小 5x5
self.conv1 = nn.Conv2d(3, 6, 5)
# 池化層,2x2 的最大池化
self.pool = nn.MaxPool2d(2, 2)
# 第二個卷積層:輸入通道 6,輸出通道 16,卷積核大小 5x5
self.conv2 = nn.Conv2d(6, 16, 5)
# 全連接層(全連接神經網路),接收 16x5x5 的輸入,輸出 120 維特徵
self.fc1 = nn.Linear(16 * 5 * 5, 120)
# 第二個全連接層,輸入 120 維特徵,輸出 84 維特徵
self.fc2 = nn.Linear(120, 84)
# 第三個全連接層,輸入 84 維特徵,輸出 10(我們的分類數量是 10,例如飛機、汽車等)
self.fc3 = nn.Linear(84, 10)
# forward 函數定義了資料在模型中的前向傳播過程
def forward(self, x):
x = self.pool(F.relu(self.conv1(x))) # 第一個卷積層,ReLU 激活函數和池化
x = self.pool(F.relu(self.conv2(x))) # 第二個卷積層,ReLU 激活函數和池化
x = x.view(-1, 16 * 5 * 5) # 攤平成一維向量
x = F.relu(self.fc1(x)) # 第一個全連接層,ReLU 激活函數
x = F.relu(self.fc2(x)) # 第二個全連接層,ReLU 激活函數
x = self.fc3(x) # 第三個全連接層,輸出分類結果
return x
# 創建一個模型實例
net = Net()
這段程式碼定義了一個簡單的卷積神經網路(CNN)模型,我們可以使用 Pytorch 內建的函示來建構這個模型。該模型包括兩個卷積層,兩個最大池化層,以及三個全連接層。每一層都定義了相應的輸入和輸出通道數,以及卷積核大小或全連接層的輸出維度。模型的forward 函數定義了資料在模型中的前向傳播過程,包括卷積、池化和全連接層操作,並使用 ReLU 激活函數。這是一個用於分類圖像的簡單 CNN 模型,可用於訓練和測試。
在深度學習中,損失函數(Loss Function)用於衡量模型的預測與實際值之間的差距。我們需要最小化這個損失函數,以使模型能夠做出更準確的預測。對於分類任務,常見的損失函數是交叉熵損失函數(Cross-Entropy Loss),也稱為 Log 損失。在 PyTorch 中,我們可以使用 torch.nn.CrossEntropyLoss() 來定義這個損失函數。以下是一個示例:
import torch.optim as optim
# 定義損失函數
criterion = nn.CrossEntropyLoss()
# 定義優化器 (Optimizer)
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
訓練模型是深度學習中的一個重要步驟。我們將使用訓練數據集(trainloader)來訓練我們的模型。訓練過程通常包括以下步驟:
for epoch in range(2): # 迭代兩個訓練周期
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# 獲取輸入數據
inputs, labels = data
# 將參數梯度清零
optimizer.zero_grad()
# 前向傳播 + 反向傳播 + 優化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 顯示損失
running_loss += loss.item()
if i % 2000 == 1999: # 每2000個 mini-batch 顯示一次
print(f'[{epoch + 1}, {i + 1:5d}] loss: {running_loss / 2000:.3f}')
running_loss = 0.0
print('Finished Training')
在上面的示例中,我們使用了隨機梯度下降(SGD)優化器來更新模型參數,並在每個 mini-batch 上計算損失。請注意,這只是一個簡化的示例,實際的訓練過程可能會更複雜,包括學習率的調整、模型保存等等。
訓練完成後,我們需要使用測試數據集(testloader)來測試我們的模型的性能。通常,我們會計算模型在測試集上的準確性(Accuracy)來評估模型的表現。以下是一個示例:
correct = 0
total = 0
# 不需要計算梯度,設為 evaluation 模式
net.eval()
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Accuracy on the test dataset: {100 * correct / total}%')
在上面的示例中,我們將模型設置為 evaluation 模式(net.eval()),然後使用測試數據集進行預測。最後,我們計算並顯示模型的準確性。
這樣,我們就完成了帶過基礎深度學習的概念,包括資料處理/準備、定義模型、定義損失函數、訓練模型和測試模型。希望這些示例能幫助您更好地理解深度學習模型的訓練過程。繼續前進,我們將深入探討更多有關人臉技術的主題!

